
先啰嗦几句,然后把时间交给今天的主角:Joker。
初次认识Joker应该是2019年的成都线下分享会,简短的几句交谈,就深刻感受到他对Google SEO的那份激情和热爱,后来发现,他确实有两把刷子,为了验证行业那些所谓的SEO“理论”,他会亲自动手去试验,得出自己的结论和观点,不盲从,是个实打实的实战派。
所以,今年的成都线下分享会,我也邀请他做了个演讲,他还专门把自己的演讲内容整理成了下面的干货长文,不多说,大家欣赏吧。
P.S. 本篇也开赞赏,所得收入将和上篇一样,通过微信转给演讲嘉宾,图为上篇给嘉宾修心哥的转账记录。
![]()
Hello大家好,我是Joker,一个卖软件的,距离上次写文章已经是2年前(2018年最后的一篇文章),这期间本来有想过再写点东西,不说月更,一年更一次吧,不过迟迟未能兑现,一是因为国内这个分享环境确实不怎么健康,二是因为确实公司、个人的事情比较多和杂(哈哈,其实就是因为懒)。
这次有幸参加英文SEO实战派的成都线下分享会,发现大家的积极性都挺高的,特别是那些从外地专程打飞过来的朋友,搞的我还有点小紧张(有种10多年前见网友的样子,哈哈), 还有更多John的粉丝没办法赶到成都来的 ,所以就有了今天这篇文章,大部分还是在会上所分享的内容。
好了,准备好瓜子花生,发车了。这次的内容比较多,你可能需要分几天来看完,哈哈。
今天的主题为“SEOER容易陷入的数据指标困惑”,主要分为以下四个部分,里面涉及到的内容主要来自于一些群友们经常提到的问题。
外链篇: DR值(Ahrefs),DA值(Moz Toolbar)、Authority Score (SEMrush) 等数据指标越高表示网站权重越高?质量越好?外链数量越多越好?能否有一个相对准确的量化标准?
内容创作篇:文章的字数越多越好?2000字的文章是标准吗?文章需要保持更新吗?
网站体验篇:停留时间越低表示页面体验越差?跳出率越高表示页面质量越差?
结语:作为SEOer,“数据指标”是衡量SEO效果的标准吗?我是从哪些方面去做网站SEO自审的?
1. 外链篇
DR值(Ahrefs),DA值(Moz Toolbar),Authority Score(SEMrush) 等数据指标越高表示网站权重越高?质量越好?
这个问题相信是很多SEOer比较头疼的问题,特别涉及到需要买外链(虽然不是太赞成,不过有时候实在没有其他办法,用钱解决的还是不错的),发Guest Post啊,找第三方的SEO服务,如何判断一个网站有没有价值,大部分人希望能有一个直观的“数据指标”作为参考。
2016年以前,大家判断一个网站的权重也好,价值也好,大部分都会以Google官方的Page Rank(PR)来作为参考指标,不过,Google Toolbar PageRank (PR) 2016年4月停止了更新。
注:这里我们需要注意,Google只是停止了 Toolbar 的PR值更新,并不代表Google就取消了PR,我相信他在背后依然有一套他的计算方式,只是他不会以具体的指标形式展示出来而已,大家有兴趣的话,可以思考下,谷歌为什么这么做。
随着PR工具条的取消更新,市场上就涌现出大批第三方的工具来帮助站长们分析网站(有需就有求),其中比较知名的就有Moz, Ahrefs 和SEMrush,这三家也分别给出了各自对于网站权重判断的数据指标,DA值(Moz),DR值(Ahrefs)和AS值(SEMrush)。一时间,大家仿佛又找到了新的方向,从追求PR值转到追求DA, DR值。
那么DR值(Ahrefs),DA值(Moz),Authority Score(SEMrush) 等数据指标越高表示网站权重越高?
我们先来看看,这几家各自对于这些“指标”的说明,这里我们以Moz和Ahrefs为例:
DA 值 (MOZ)
Domain Authority (DA) is a search engine ranking score developed by Moz that predicts how likely a website is to rank on search engine result pages (SERPs). https://moz.com/learn/seo/domain-authority
What is a “good” Domain Authority? Generally speaking, sites with a very large number of high-quality external links are at the top end of the Domain Authority scale, whereas small businesses and websites with fewer inbound links may have a much lower DA score. Brand-new websites will always start with a Domain Authority score of one.
https://moz.com/learn/seo/domain-authority
DR 值 (Ahrefs)
Domain Rating (DR) shows the strength of a website’s backlink profile compared to the others in our database on a 100-point scale. It’s essentially a less granular version of Ahrefs Rank (AR). https://help.ahrefs.com/en/articles/1409408-what-is-ahrefs-domain-rating
When a domain’s DR is higher, more “link juice” is transferred to linked domains. The source domain splits its rating equally amongst the domains it links to. So: a DR-10 domain which links to three other domains can influence your DR more than a DR-80 domain which links to a million other domains. https://help.ahrefs.com/en/articles/1409408-what-is-ahrefs-domain-rating
从这两家各自的描述可以看出,不论是DR值还是DA值,他们的计算方式基本上都是基于“Link数量”和“Link质量”(他们自己的计算方式),也只是第三方工具自家的计算方式,并不代表Google背后的PR值。
而且这个判断标准跟网站自身的“内容相关性”,“专业度”,“权威度”没有任何关系。自然也就有了很大的“人为”可控的操作空间,就会出现很多专门为了“做数据”的网站。
所以,如果我们单纯的以这些“数据指标”来作为判断依据,必然会陷入一些“坑”里。
这里我们来看几个例子,我以Ahrefs的DR为例:
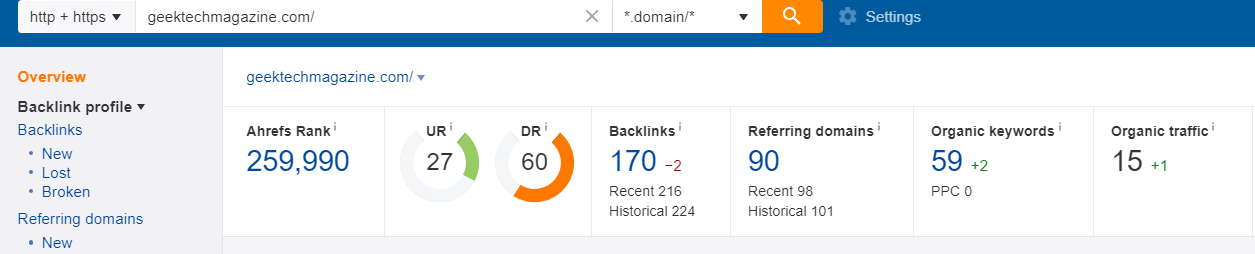
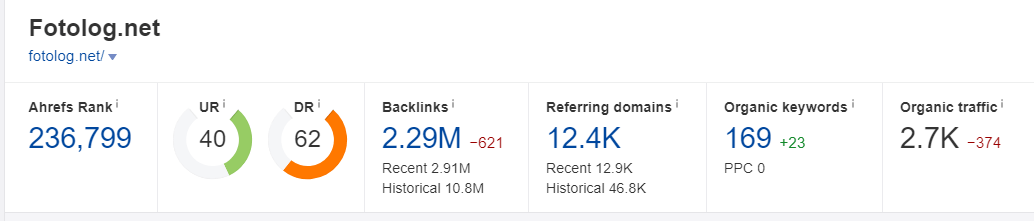
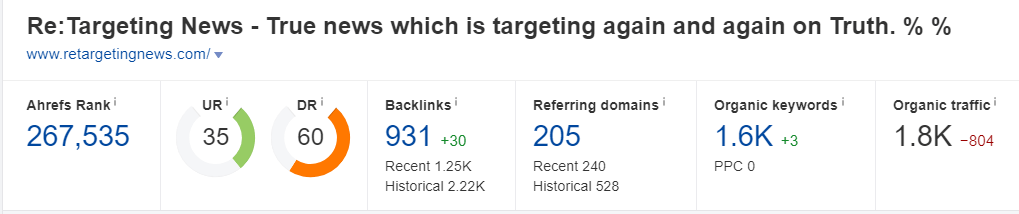
(我是卖软件的,这3个tech站也是我同事在做资源扩展的时候发现的)
单纯从DR值来看,这3个站都是DR 60以上的站点(在大部分SEO人的观念中,DR 60以上的站点都是“优秀”的)。但这3个站点的“数据指标”都有很大的概率是人为做的,如果你花个80刀- 120刀,或者给他提供一篇优质的Guest Post来换取一条反链的话,其实并没有那么高的价值(你可能还以为你赚了)。
如何判断一个站的这些“数据指标”是不是人工做的呢?
这里我们以 geektechmagazine.com 为例,使用Ahrefs工具,我们主要看:
Organic Keywords(关键词覆盖量)
Organic traffic (关键词预估流量)
网站内容收录量
流量趋势
建站时间(通常有价值的站点都不会是建站2年内的,部分更换域名做了301的除外)
Top Page内容(判断是否与你的行业内容相匹配)
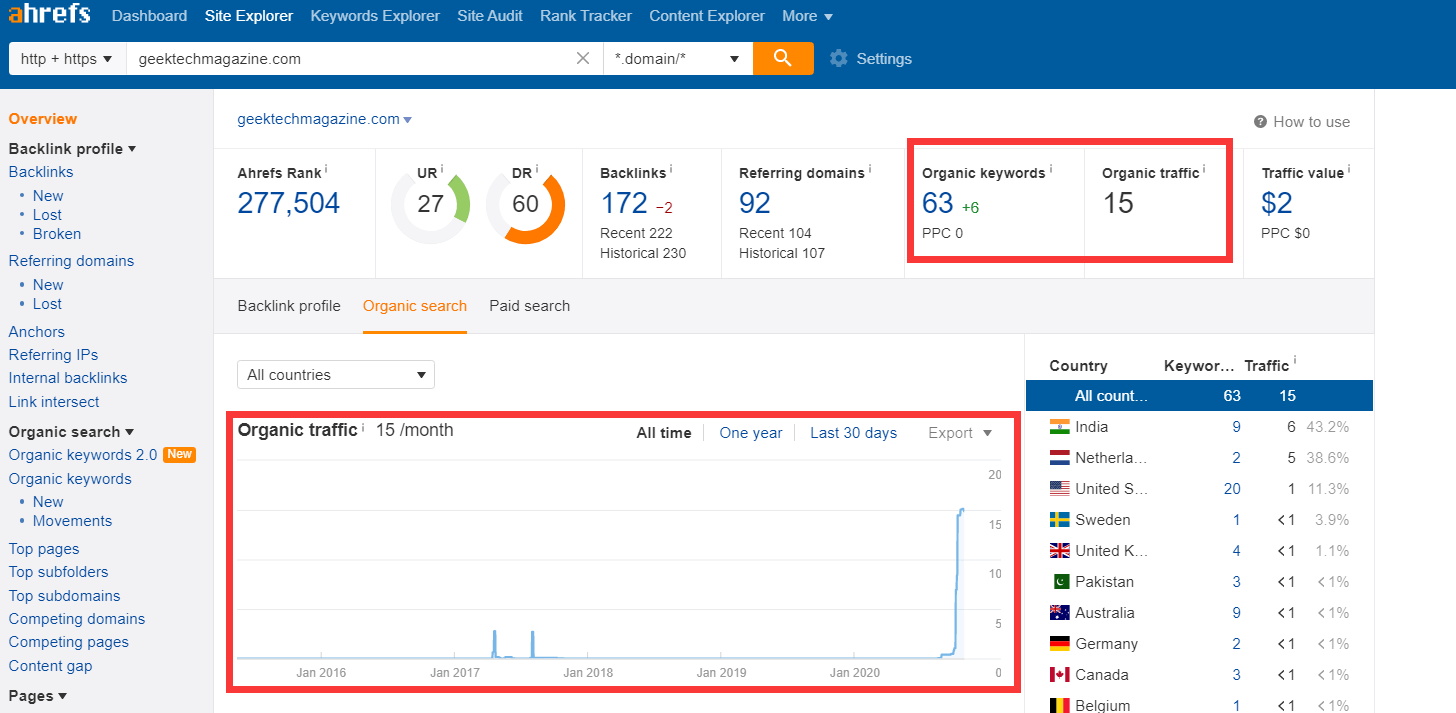
一个DR 60的站点,关键词覆盖量却只有几十,预估流量也只有几十,这说明这个站点其本身的关键词覆盖量,排名能力基本为0。我们知道“权重”这个概念本身是通过Link来传递的,而“权重”的体现,我们可以理解为在某些关键词的覆盖量和排名上,有优势的表现。
因此像例子中的这个站点,其本身并没有这种优势体现,自然也就没有“有价值的权重”来传递,那么我们从这样的网站获取的反链也就失去了其本身的价值。
Joker观点:
DR值,DA值这类“指标”本身并不能作为一个网站权重高低的直接判断标准,需要结合其他多项指标综合判断,避免陷入“数据站”的陷阱。需要综合判断:
建站时间
关键词覆盖量,预估关键词流量 (这2点其实要刷也可以刷,不过手法就高明多了)
Top Page数据量,以及其内容相关性 (这点非常重要,不是想刷就能刷得了)
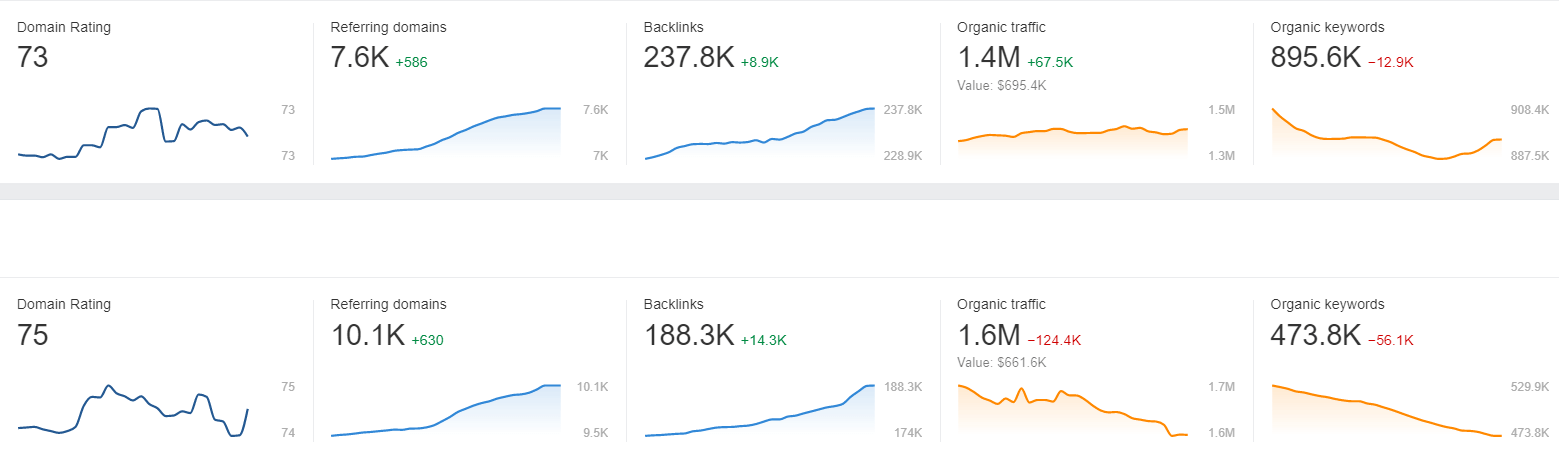
这里,我们可以看看我自己的2个站点,其DR值与关键词覆盖量,预估流量的关系比例:
好了,上面我们说了外链的“质量指标”,下面我们来看看另外一个点:外链的“数量指标”。
“外链数量越多越好?能否有一个相对准确的量化标准?”
这个问题如果放在2016年以前,我可以肯定的给你回答 “YES”,外链数量越多越好。
但是,现在我个人认为可以说 NO,为什么呢?
来看看Google官方的一个关于“链接”的专利,这个专利叫“Producing a ranking for pages using distances in a web-link graph ”
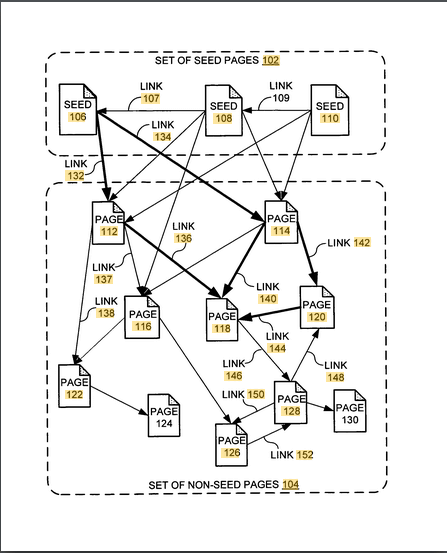

这个专利其实在2006年的时候就有了,但我个人感觉,Google公司在那个时候并没有利用,真正开始利用是在2015年以后(个人猜测),想想2016年的“企鹅更新4.0”的主要内容,再来结合这个专利看看。
该专利的信息来源(感兴趣的朋友们建议看看原文):
Bill Slawski 解读:https://www.seobythesea.com/2018/04/pagerank-updated/
这里,我摘取了Zac老师关于这个专利的一些重点总结:
1. 概要:新PageRank不再计算导入链接的总数,而是计算这个页面与种子页面之间的距离,距离越近,页面质量越高,页面级别、新PageRank越高。
2. 种子页面的特征:种子页面显然是高质量的页面,专利里举的例子是Google目录(如DMOZ,这个目录已经死掉了)和纽约时报。种子页面需要与其它非种子页面有很好的连通性,有比较多的导出链接指向其它高质量页面。种子页面需要稳定可靠,有多样性,大范围覆盖各类主题。
https://www.seozac.com/google/google-new-pr/
3. 链接的长度:页面导出链接越多,链接长度越长。这和原始PageRank思路是一样的,导出链接越多,每个链接分到的权重越少。链接所在位置越重要,比如正文中,正文靠前部分,链接长度越短。链接锚文字字号越大,或者在H1中,可能链接长度越短 https://www.seozac.com/google/google-new-pr/
这里顺便提醒下那些还在做Footer或者侧边栏全站链接的,停停吧,风险很大;另外,关于链接锚文字字号越大可能链接长度越短这个观点,不太清楚Zac老师是怎么得出的,专利原文只提到了字体,并未提及其他。
4. 链接距离:链接距离就是页面与种子页面集合之间的最短链接长度之和。如果一个页面无法从任何种子页面出发访问到,也就是种子页面集合到这个页面完全没有链接通路,那么链接距离是无限大。然后Google算法根据链接距离计算出一个页面的排名能力分数,也就是新PR值,最后的排名算法中,这个新PR值作为排名因素之一。也就是说,链接距离越短,离种子越近,Google认为页面越重要,排名能力越高。
如果一个页面从种子集合完全没有链接通路可以到达,也就是前面说的链接距离为无限大,这个页面将被排除在简化链接网络图之外。如果一个页面得到的链接都来自简化链接网络之外,虽然链接总数可能很大,但其链接距离依然是无限大。
https://www.seozac.com/google/google-new-pr/
从上面的信息我们可以得到,在这套算法下,外链的“总量”不再是计算价值的标准了,取而代之的是与“种子页面”的通路,也可以理解为相关站点或者权威站点的反链量。
Joker观点:
“外链数量”并没有一个明确的指标来衡量想要获得XX排名、需要多少数量的外链。
“发外链”是无法获取高质量、高相关度的反链。
Outreach的核心目的不是外链,而是这个资源,这个人。
我心中最优质的外链来源方式是被动获取。
注:上面所说的“发外链”主要指的做一些常规的WEB 2.0链接,博客评论链接,profile,垃圾 guest post 之类的,想想看啊,你人工能发的这些内容,都可以通过机器实现,你认为你能发得过机器吗?不过这个还是取决于行业竞争度,我最近在研究一些B2B的领域,发现他们并不需要什么优质的反链,做好网站自身构架和内容就行了,因为整个行业的竞争度还没有达到需要通过优质反链来竞争的地步。
被动获取,指的是通过创优质的内容 (这个内容不限制形式,文字,图片,视频,数据,工具),让别人主动把你的信息作为引荐来源,自然就能获取到高相关度的反链,这也是外链本身最初的作用。如果有做软件的朋友,其实我们做软件的在内容提供上,要比其他领域更多一个优势,我们可以通过提供一些实用的小工具,供第三方平台使用,从而获取更多的流量来源以及自然链接(想想Youtube的嵌入式代码,各种工具的插件)。
2. 内容创作篇
文章的字数越多越好?2000字的文章是标准吗?
自从近几年大家都开始流行内容创作以来,“文章字数”(word counts)这个指标似乎成了判断文章质量好坏的标准之一。

Long Content(长文)策略我是从2016年开始执行的,当时给顾小北的一篇投稿中也提到过这个问题。
你从国外的一些业内大神的分享中,也会发现,各种Long Content的好处,比如:
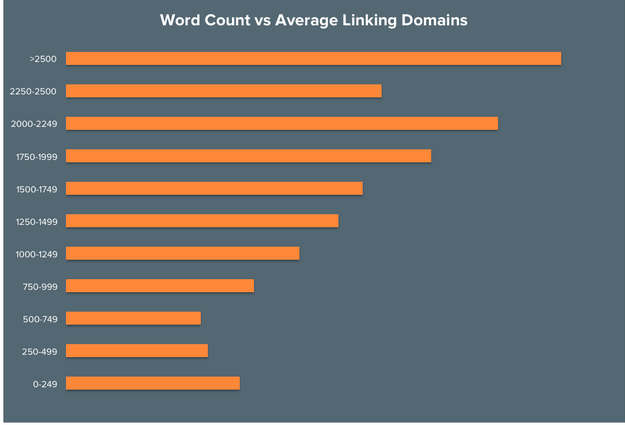
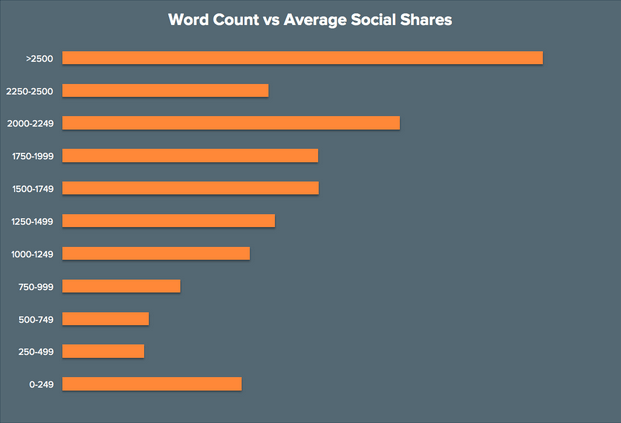
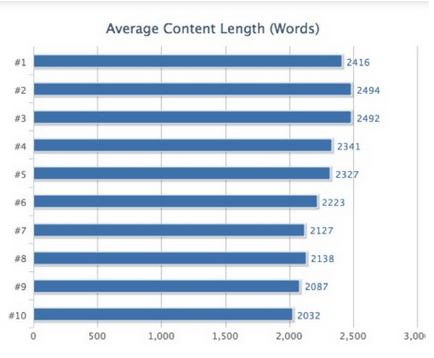
看着各种分析报告,越来越多的SEOer就开始迷惑了,对手写了篇1500字的文章,我想超越他,就得写3000甚至4000字?真的要这样吗?我们需要去创作超过“2000”词的文章?
Joker观点:
文章字数从来不会成为Google算法评判的一个标准。
不论对于用户还是Google,真正需要的是Deep Content。
Long Content 不等于 Deep Content。
Deep Content的内容长短取决于你选择的话题,这本身并没有明确的字数指标。
什么是Deep Content?
我的理解是尽可能多的去覆盖与用户搜索核心话题相关联的内容,从而达到让用户了解更多相关知识信息的目的。
举个例子:比如用户搜索话题为 “mouse dpi”,以前拿到这个话题,大部分SEO人估计就会直接开始介绍“mouse dpi”的内容,但通过 Deep Content 分析,我得到的结论是,需要覆盖的内容包括:
what is mouse dpi
how to check mouse dpi (mouse dpi changer)
how to change mouse dpi (mouse dpi checker)
mouse dpi test
mouse dpi for gaming
mouse dpi setting
来看看我这篇基于 Deep Content 的成文效果:
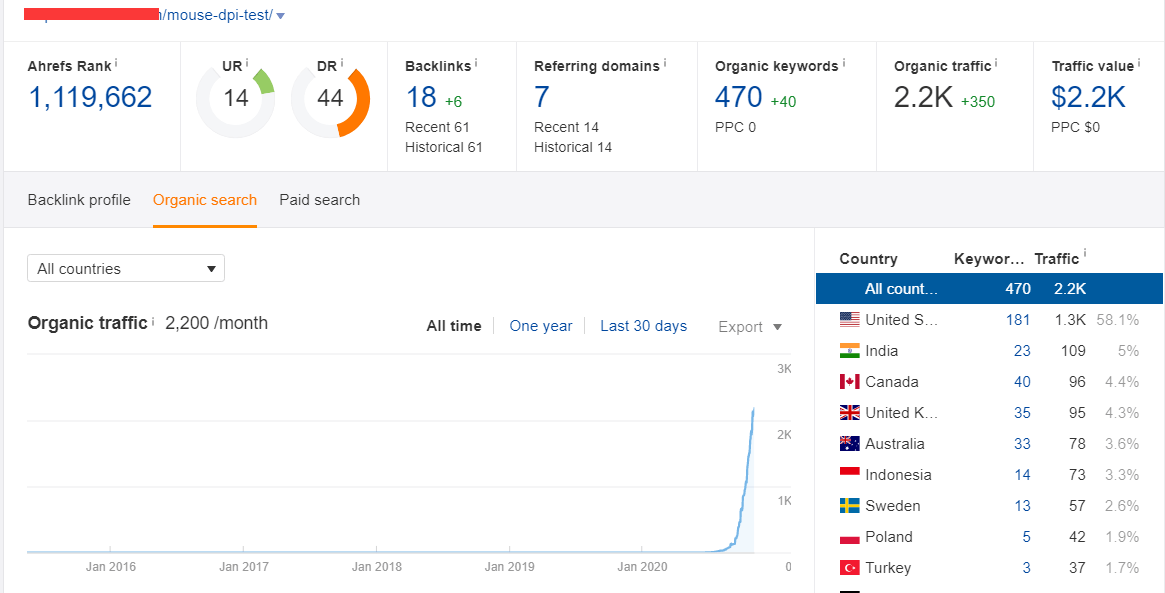
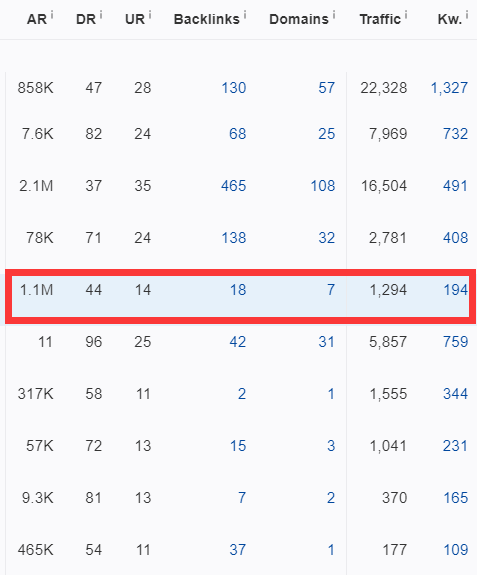
这篇文章是7月上线的,而且是上在了我一个今年6月才上线的新站上面(全新站点,域名,服务器,都是全新的,主要用于做一些测试),在首页上和我竞争的那些站点,要么是网站自身DR碾压我,或者是在外链上碾压我。但我可以通过内容构架搬回一点劣势,从而挤进首页。
如何做Deep Content分析?
根据搜索词,分析排名前20的页面内容(了解各个网站对于这个话题的关注点有哪些,其中特别需要注意出现在0排位的页面内容,另外,其实很多在第二页的内容非常有价值,但他可能本身站点SEO做的较差所以无法挤进前10,但我们可以好好利用)
利用“提示性关键词”了解用户在搜索这个话题的时候容易触发哪些相关词
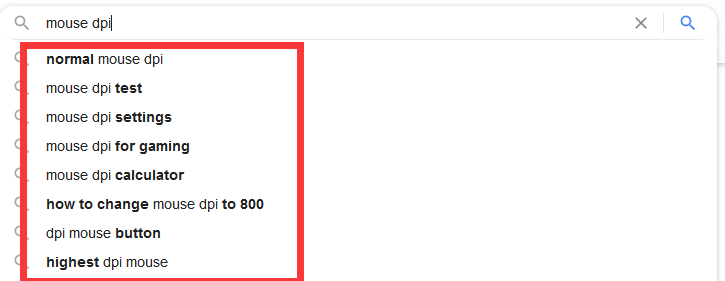
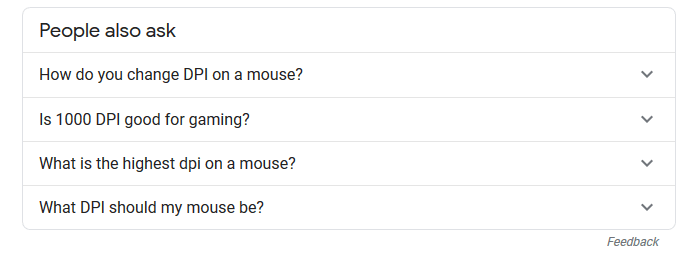
利用“people also ask”这个栏目来了解话题相关信息
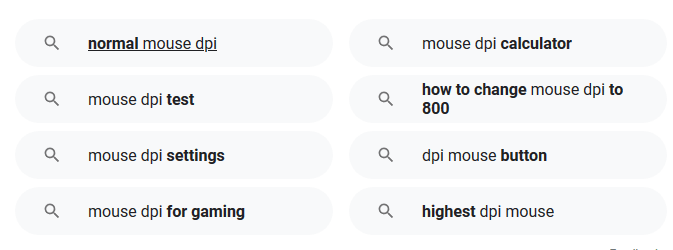
利用“Related Search”了解用户相关搜索
当然也可以利用一些第三方的分析工具帮忙。比如:Ahrefs Keywords Explorer,Ubersuggest等关键词工具(收费),还有备选工具:MarketMuse,不过价格偏贵,且功能较为单一。
通过上面的分析思路,就能得到一份不错的数据报告了,让你从构架上思考如何把内容做到“Deep”。
3. 网站体验篇
停留时间越低表示页面体验越差?跳出率越高表示页面质量越差?关于这个问题,我们先来看看Google官方对“跳出率”的一个定义:
A bounce is a single-page session on your site. In Analytics, a bounce is calculated specifically as a session that triggers only a single request to the Analytics server, such as when a user opens a single page on your site and then exits without triggering any other requests to the Analytics server during that session. https://support.google.com/analytics/answer/1009409
在 Google Analytics(GA)中,“跳出”特指仅触发了一次对GA服务器的请求会话。例如,用户打开了您网站上的一个网页,然后就退出了网站,并且这次会话没有触发对 Google Analytics 服务器的任何其他请求。
所以我们可以看到,单看 “跳出” 这个行为其实本身并没有体现出用户对于当前页面是否满意,仅仅是表示用户通过当前页面退出,并没有和其他页面再次发生互动。
那么“高跳出率”是不是就表示不好呢?我们还是来看看Google官方的一个解释:
It depends. If the success of your site depends on users viewing more than one page, then, yes, a high bounce rate is bad. For example, if your home page is the gateway to the rest of your site…then you don’t want a high bounce rate. On the other hand, if you have a single-page site like a blog…, then a high bounce rate is perfectly normal. https://support.google.com/analytics/answer/1009409
从这里我们可以看到,高跳出率其实是要根据我们不同的页面目的来做区分的:
情况 1:对于首页,目录页等具有导航性质的页面,我们的主要目的是为了让用户通过当前页面浏览我们更多的内页,这种情况,高跳出率肯定就不是什么好事了。
情况2:对于文章页,特定的专栏页,如果该页面本身提供的信息已经满足用户的基本需求,比如用户想了解某个知识或者某个问题的解决方案,他进入该内容页后,内容提供的非常详细,满足了他的需求,这种情况,跳出率高也就可以被接受了。
但这里我们还需要借助另一个指标“停留时间” 来综合判断。
简单来说,对于内容页,高停留时间、高跳出率是可以被接受的,但低停留时间、高跳出率就不行了。
当然除了“停留时间”,我还可以利用GTM (Google Tag Manager)来设置一些事件,比如用户对于当前页面的浏览深度,行为按钮点击,来进行综合判断当前页面是否满足了用户的某些需求,这里就不一一详细列举了(最近看了新的GA4.0,还不错,里面直接把“scrolling”数据体现出来了,感兴趣的朋友可以看看,GA4.0最大的提升就是在一些用户交互的数据方面比老版的做的更好,我也在研究学习ING)。
来看看我自己网站的列子:
我的首页

我首页的主要目的是“引导用户访问我更多的内页”,所以我们可以看到虽然平均停留时间只有“45秒”,但我的跳出率却只有“17.17%”。
再看看我的文章页:
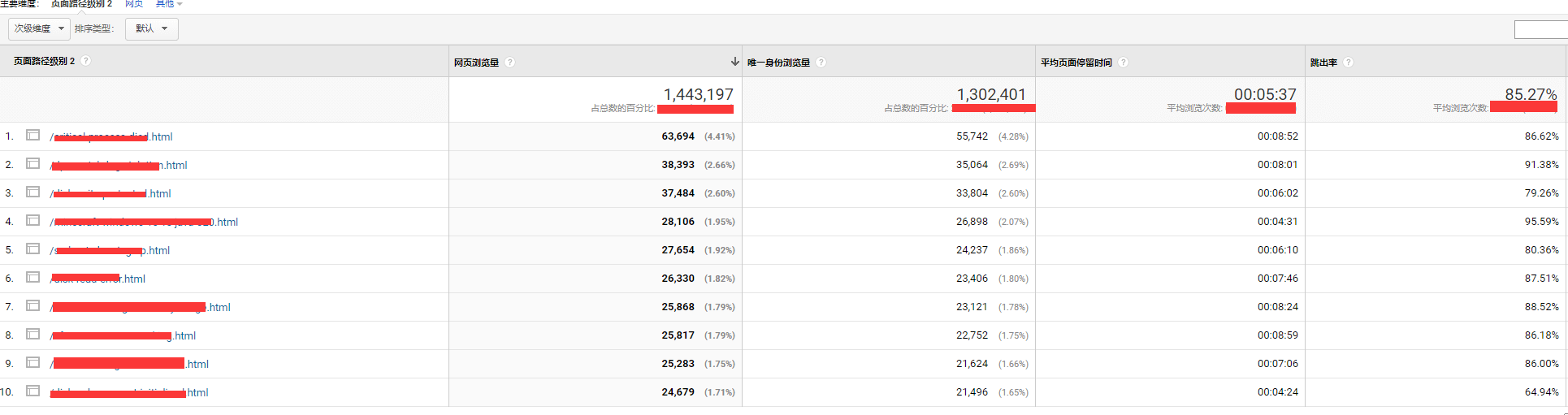
我们可以看到,虽然文章页的跳出率达到了85%,甚至部分页面达到了90%,但他的停留时间却能达到6,7分钟以上,TOP 1流量的文章可以达到8:52秒的停留时间。
而我通过“Crazy Egg”等热力图工具以及屏幕录像工具(Crazy Egg自带),也可以看到用户访问我文章页的真实浏览动态,从而得知用户真实的访问体验。
Joker观点:
跳出率和停留时间这两项指标,单独来看,其本身并不能反映页面质量是否满足用户需求。
是否需要降低跳出率取决于页面本身的目的,降低跳出率主要从以下几点出发:
根据不同的流量来源渠道,分析我们的着陆页是否满足渠道来源的用户需求。
页面内容的可视性是否友好,比如针对移动端用户的优化体验。
增加页面的内链建设,推荐引导用户阅读更多相关内容。这里需要注意下,对于 Deep Content 通过内链增加的方式引导收效甚微,因为如果页面内容本身已经满足了用户的基本需求,则很难引导用户访问更多内容了。
检查所有页面的跟踪代码是否添加正确。之前帮一个朋友分析网站,最后发现是因为他新增的一些页面没有正确添加跟踪代码,导致从一些Landing Page页面访问了更多的内页,但没有实现到跟踪。
增加停留时间
决定用户在内容页上的停留时间,主要由以下几方面决定:
#1: 内容相关度,内容深度,内容的多样性(如文字,图片,视频等),以及文章的排版,阅读逻辑引导来决定。
#2: 内容深度:很好理解,前面我们在讲 Deep Content 的时候已经提及过了。
#3: 内容的排版,阅读逻辑引导,字体大小,颜色。这里我们需要注意下Google 目前对于内容的content readability 和content accessibility开始有一定的判断了,在lighthouse中已经出现了根据对比度来作为判断的指标,感兴趣的朋友可以去看看。
#4: 内容的多样性。这里主要强调的是视频,在我们的文案中嵌入相关的YouTube视频能够大大提升单页的停留时间。嵌入视频的另外一个好处就是可以增加YouTube上的视频观看量和相关的用户数据,从而提高我们视频在YouTube的站内搜索排名,进而收割YouTube本身的流量。
4. 结语
作为SEOer,“数据指标”是衡量SEO效果的标准吗?
Joker观点:
SEOer的核心目的是从搜索引擎获取“有效”的流量,达成相应的转化。所谓的“数据指标”,不论是DR值,DA值,外链数量,文章数量,LIGHTHOUSE得分,其本身并不是我们的目的。
真正需要关注的“数据指标”包括:
第一,网页加载速度。
越快越好,这个没有一个实际的标准,比如说加载时间10秒就不好,9秒就好 , 当然这还有一个前提,你所提供的内容本身是符合用户需求的,而不是说我只要快就可以了。
网页加载速度我们可以分为2个方面来看:
A. 技术端:比如网站自身大小,服务器本身的稳定性,JS, CSS等文件的大小,请求数量,图片信息大小。
注:网页加载速度,我们需要注意一个值Time to First BYTE(TTFB, 推荐测速工具:wbpagetest.org)
B. 用户端:用户本身的网络情况,设备情况 (从GA里面能找到详细的相关报告),服务器与用户的位置关系(一般来说使用CDN可以有效解决)。
这点我们尤其需要注意,不要只盯着看GA报告里XX页面加载时间都需要5秒, 6秒了,如果某个页面的加载速度真的远低于平均水平了,那么我们需要进行细分报告, 比如GA中我们可以查看,某个页面的具体用户的设备,地理位置等。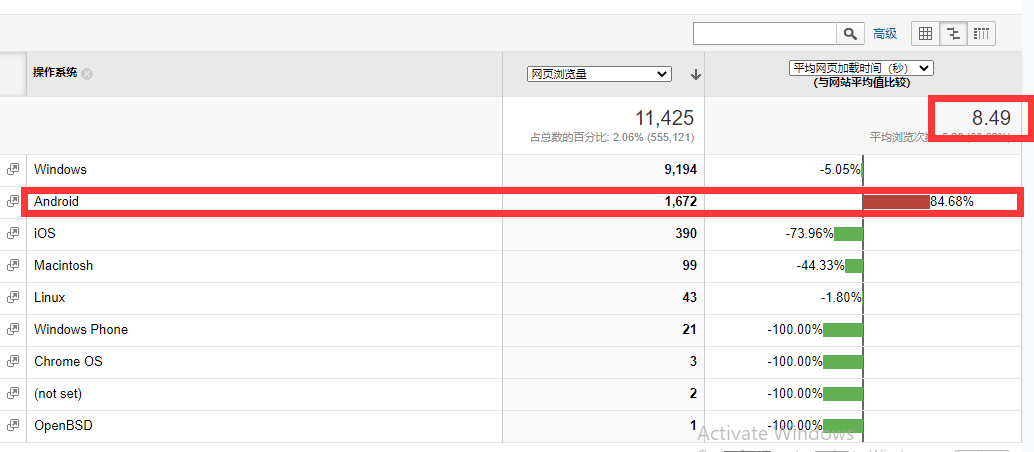
比如:我某个页面加载速度达到了8.49秒,远高于平均水平,但经过仔细细分,发现是“Android”的用户问题,而安卓平台本身不是我主要考虑的优化方向(这个要根据你的业务,资源,人力,技术)来权衡,是否需要投入到对应的优化中。
第二,在SERP里的点击率“CTR”。
这个是已经明确了的一个影响算法的大因素。
第三,收录率。
随着Google不断的变化,特别是近两年,大家可以发现能“人为操控”的地方越来越少,取而代之的,更多是一些较为模糊的概念,比如前面提到的“seed page”,比如 EAT (Expertise-Authoritativeness-Trustworthiness) 的评判,所以其实希望大家把更多的精力花在自己的网站、产品、内容上,服务好自己的用户才是我们最根本的目的。
我是从哪些方面去做网站SEO自审的?
大部分人对SEO的评判仅停留在 “内容”和“外链”这2部分上,但,我认为还应该加入Tech端的,近几年,分析了很多网站,不论竞争激烈的行业,还是传统的B2B行业,其实他们大部分最核心的问题,并不是在内容和外链上,而是在网站的“基本技术上”。
我们都知道搜索引擎蜘蛛的简单流程是:
爬行 => 抓取 => 索引 => 渲染 => 排名
其实,首要解决的就是BOT的“Crawl accessibility”, “Google bot”其本身也是一个程序,是程序就得消耗“资源”,存在消耗,他就会有个 Crawl Budget ,而我们需要做的是通过技术让bot在有限的budget内抓取到我们希望的内容,并指导它理解内容。
好了,下面看看我一般从哪些地方去做SEO自审(SEO Audit)。
 今天由于时间有限,就先分享到这了,下次有时间,我会把上面这个流程具体涉及到的相关点总结出来。
今天由于时间有限,就先分享到这了,下次有时间,我会把上面这个流程具体涉及到的相关点总结出来。
再次感谢John能提供这个机会跟大家分享,国内的分享环境需要这股“清流”,不然到处都是“坑”。
我是Joker,一个卖软件的,谢谢大家!收获从分享开始!
实践主义者,满满的干货,大赞!
请问可以转载文章吗?
来信询问,转载哪一篇。
感谢Joker的分享!讲得非常详细,一篇文章的深度足以让人研究30分钟,哈哈哈。应该是minitool大佬,甚是佩服。
干活慢慢,感谢感谢!